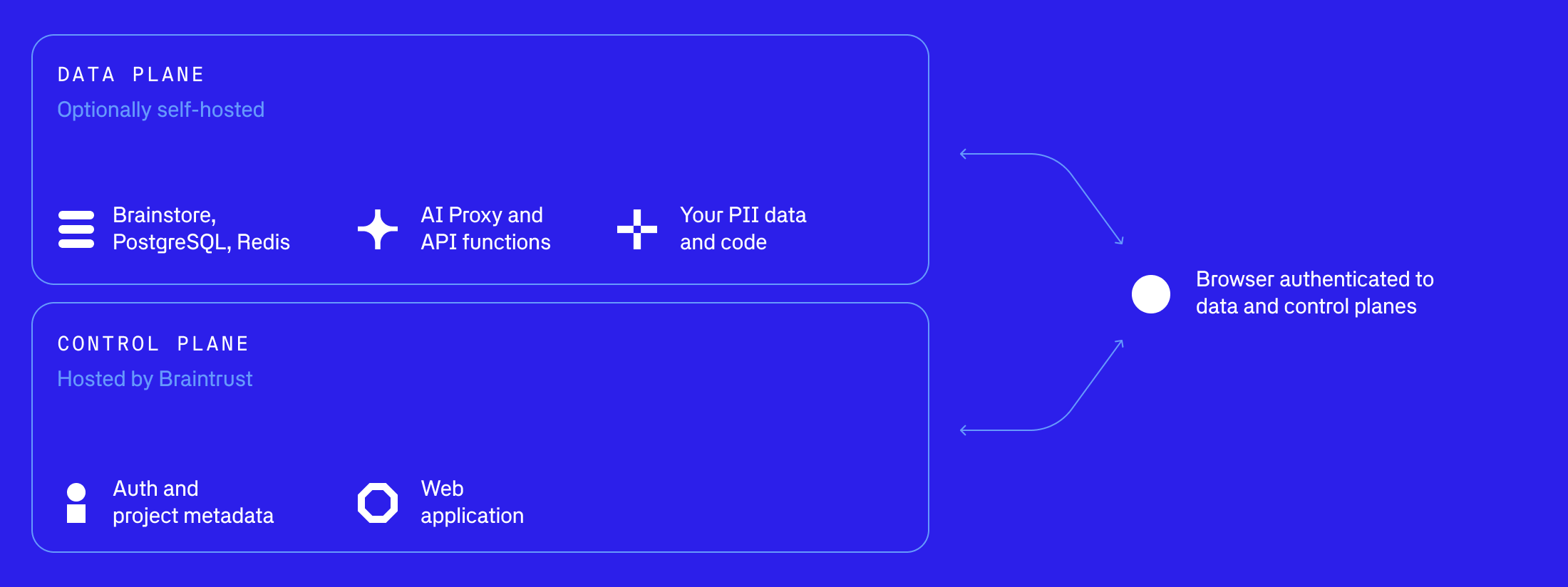
Control plane
The control plane manages the web UI, authentication, user management, and metadata storage (project names, experiment names, organization settings). It lives in Braintrust’s managed service and is delivered as SaaS. The control plane does not store or process your sensitive AI data — it communicates with your data plane only for authentication and metadata synchronization.Data plane
The data plane stores all sensitive AI data — experiment logs, traces, spans, datasets, and prompt completions. When you use Braintrust’s SDKs, they send data directly to your data plane, never touching Braintrust’s servers. When you use the web UI, your browser communicates directly with your data plane via CORS. For hardware sizing requirements for all data plane components, see Hardware requirements.API service
The API service is the entry point for all SDK and browser requests to the data plane, built in TypeScript/Node.js. On AWS, it runs on ECS (Terraform module v6.0 or later), split into three services by workload (braintrust-api for general traffic, braintrust-api-ingest for ingestion, and braintrust-api-background for evals, function invocation, and proxy traffic). Versions prior to v6.0 run on Lambda. On GCP and Azure, the API runs as Kubernetes containers that you manage and scale.
PostgreSQL
PostgreSQL stores metadata required to operate the platform, including pointers to raw data in object storage and aggregate statistics about the data. It is not the primary store for your AI data. Traces, spans, and logs live in Brainstore and object storage.Redis
Redis provides caching and coordination for session management, rate limiting, and Brainstore transaction ID assignment, which ensures consistent ordering of concurrent writes.Object storage
Object storage (S3 on AWS, GCS on GCP, Azure Blob on Azure) is the durable, long-term home for all AI data. Brainstore writes every ingested span to object storage as a write-ahead log (WAL) entry and compacts those entries into indexed segments that also live on object storage. Because object storage is the source of truth, Brainstore nodes are stateless and can be replaced without data loss.Brainstore
Brainstore is Braintrust’s high-performance database for ingesting and querying AI data. It uses object storage and a streaming Rust engine to load spans in real time, cutting down on latency and enabling fast full-text search over large volumes of trace data. Each customer’s data lives in its own partition, and Brainstore treats semi-structured fields as a first-class citizen rather than shredding them into columns — which breaks down at the payload sizes AI traces produce. Brainstore runs as three distinct node types:- Writers ingest incoming spans and traces and write them to object storage.
- Readers serve ad-hoc queries, including those from the API and user-defined BTQL queries.
- Fast readers serve predictable UI queries — paginated viewers, span and trace lookups — in isolation from standard reader nodes, keeping the UI responsive while resource-intensive queries run on readers.
Write path
Every write appends to a WAL on object storage, allowing high throughput without coordination bottlenecks. In the background, two steps convert the WAL into a queryable index: Processing assigns records to time-ordered segments (ensuring all spans for a trace land together), and compacting converts those segments into efficient indexed formats including inverted indexes, row stores, column stores, and bloom filters. Indexing is asynchronous and continuous — the system is always improving its read-optimized representation of the data.Read path
Brainstore runs an explicit query pipeline: Parsing SQL into an AST, binding names to schemas and fields, optimizing by pushing down filters and pruning unneeded fields early, then executing against the index to stream results. Full-text search across prompts and responses is a first-class query path. Reads are not forced to wait for compaction — when you query, Brainstore merges data from the WAL, processed-but-not-yet-compacted entries, and fully indexed segments, keeping queries real-time as background compaction proceeds.Where data is stored
Next steps
- Deploy your data plane — Set up Braintrust in your cloud environment.
- Hardware requirements — Size your data plane components for production.
- Self-hosting overview — Understand shared responsibility, monitoring, and upgrades.